

Continúo poniendo scripts de programación en python para automatizar tareas que tengan relación con la criptografía.
Ya puse una entrada con un script en python para cifrar y descifrar textos en claro y criptogramas, respectivamente, utilizando el cifrado de Vigenère, y también puse un post con un script en python para realizar un ataque de diccionario a un criptograma cifrado utilizando este criptosistema.
Pues bien, ahora le toca el turno a un script para atacar a un criptograma de este tipo mediante otro método con objeto de descifrarlo sin conocer la clave empleada en el cifrado.

En el script que pongo en esta entrada, en primer lugar se realiza el ataque utilizando el método Kasiski, y si el máximo común divisor de las distancias que separan las secuencias de tres o más caracteres repetidas en el criptograma es 1, se avisa de esta circunstancia y el script da la posibilidad de probar con un tamaño de secuencias repetidas mayor. En este caso, por tanto, la longitud de la clave no es el máximo común divisor de las distancias que separan todas las secuencias de tres o más caracteres, sino que puede que sea el máximo común divisor de algunas de ellas; las de mayor tamaño. En cualquier caso, si no se encuentra un máximo común divisor diferente de 1 tras las pruebas que se realizan, el ataque finaliza. En esos casos se puede utilizar el ataque mediante el Índice de Coincidencia (IC), tal y como expliqué en este post.
En caso contrario se continúa con el ataque y el script muestra el texto en claro obtenido con la clave más probable, y pregunta si éste es inteligible, para en el caso de no serlo dar la posibilidad de cambiar la clave de forma manual o de realizar un ataque de fuerza bruta a la clave con los caracteres más probables para cada uno de los caracteres de la misma.
El caso del cambio manual de la clave está previsto en el script porque en ocasiones, cuando no todos los caracteres de la clave más probable son correctos, pero sí la mayoría de ellos, se puede observar un texto en claro parcialmente descifrado, y suele ser relativamente fácil ver a simple vista qué carácter o caracteres de la clave son incorrectos.
Mientras que el ataque de fuerza bruta a los caracteres de la clave está previsto porque es perfectamente factible si falla lo anterior, ya que el script reduce el espacio de claves a probar a un tamaño más que razonable para llevarlo a cabo; sólo se considerarán los 3 caracteres más probables para cada carácter de la clave.
Si se opta por realizar el ataque de fuerza bruta, el script utiliza sendos diccionarios de trigramas (english_trig.txt) y (espanol_trig.txt), y sendos diccionarios de palabras de 4 o más letras muy frecuentes en ambos idiomas (english_word.txt) y (espanol.pala.txt).
En cualquier caso, para que el ataque de fuerza bruta funcione se necesita el siguiente módulo, que será importado en el programa principal, para el cálculo del Índice de Coincidencia (IC) de los textos en claro que se vayan obteniendo:
#!/usr/bin/env python
# -*- coding: utf-8 -*- # ÍNDICE DE COINCIDENCIA (IC): # # Cálculo del IC de un texto. # # http://mikelgarcialarragan.blogspot.com/ def calculo_ic(texto,alfabeto): # Cálculo de la frecuencia relativa de cada uno de los caracteres del alfabeto en el texto. frecuencia_relativa=[0 for caracter in alfabeto] for caracter in alfabeto: frecuencia_relativa[alfabeto.index(caracter)]=texto.count(caracter) # Cálculo del número de pares de caracteres iguales que es posible obtener del texto tomando dos de ellos al azar. pares_caracteres_iguales=[] for caracter in alfabeto: pares_caracteres_iguales.append(frecuencia_relativa[alfabeto.index(caracter)]*(frecuencia_relativa[alfabeto.index(caracter)]-1)/2) # Cálculo del número de pares de caracteres que es posible obtener del texto. pares_caracteres_posibles = len(texto) *(len(texto)-1)/2 # Cálculo del IC. ic = 0 for caracter in alfabeto: ic = ic + (pares_caracteres_iguales[alfabeto.index(caracter)]/pares_caracteres_posibles) return ic
El script es el siguiente:
#!/usr/bin/env python
#!/usr/bin/env python # -*- coding: utf-8 -*- # ATAQUE MÉTODO KASISKI AL CIFRADO DE VIGENÈRE: # # Ataque utilizando el método Kasiski a un criptograma cifrado mediante el criptosistema de Vigenère # # http://mikelgarcialarragan.blogspot.com/ import re from unicodedata import normalize import math import itertools from ic import calculo_ic # SECUENCIAS DE CARACTERES REPETIDAS: # Busca y cuenta secuencias de caracteres de una longitud dada o superior que se hallen repetidas en el criptograma, # y calcula el máximo común divisor de las distancias que las separan. def busqueda_secuencias_repetidas(criptograma,longitud_secuencias): fin_busqueda = False secuencias = [] secuencia_en_lista = False n = 0 while not fin_busqueda: for i in range(0, len(criptograma)-longitud_secuencias+1): for secuencia in range(0,len(secuencias)): if criptograma[i:i+longitud_secuencias] in secuencias[secuencia][0]: secuencia_en_lista =True break if criptograma.count(criptograma[i:i+longitud_secuencias]) > 1 and not secuencia_en_lista: secuencias.append([criptograma[i:i+longitud_secuencias], criptograma.count(criptograma[i:i+longitud_secuencias])]) n+=1 secuencia_en_lista = False if n > 0: longitud_secuencias+=1 n = 0 else: fin_busqueda = True secuencias_repetidas = [] for i in range(0,len(secuencias)): incluida_en_otra = False for j in range(i+1,len(secuencias)): if i != len(secuencias)-1 and (secuencias[i][0]) in (secuencias[j][0]): incluida_en_otra = True break if not incluida_en_otra: secuencias_repetidas.append(secuencias[i]) gcd = 1 if len(secuencias_repetidas) > 0: distancias_secuencias_repetidas = [] for secuencia_repetida in secuencias_repetidas: inicio_busqueda = 0 posicion_anterior = 0 for i in range(0, secuencia_repetida[1]): if inicio_busqueda != 0: distancias_secuencias_repetidas.append(criptograma.find(secuencia_repetida[0], inicio_busqueda) - posicion_anterior) posicion_anterior = criptograma.find(secuencia_repetida[0], inicio_busqueda) inicio_busqueda = posicion_anterior + 1 gcd = 0 for distancia in distancias_secuencias_repetidas: gcd = math.gcd(gcd, distancia) return secuencias_repetidas,gcd # FRECUENCIA RELATIVA: # Calcula la frecuencia relativa de cada caracter en un texto. def calculo_frecuencia_relativa(texto,alfabeto): frecuencia_relativa = [] frecuencia_relativa.append([(caracter, texto.count(caracter), texto.count(caracter)/len(texto)*100) for caracter in alfabeto]) return frecuencia_relativa # FUNCIÓN DE DESCIFRADO: # La función de descifrado es: Dk(Ci) = (Ci - Ki) mod n def descifrar(alfabeto,criptograma,clave): texto_claro = "" i = 0 for caracter in criptograma: texto_claro = texto_claro + alfabeto[(alfabeto.find(caracter) - alfabeto.find(clave[i % len(clave)])) % len(alfabeto)] i+=1 return texto_claro def main(): # SELECCIÓN DE IDIOMA: # Se solicita que se indique el idioma en el que se supone que se cifró el texto en claro. idioma = "" while idioma == "": print ("") print ("*** SELECCIÓN DE IDIOMA **************************") print ('1. Inglés.') print ('2. Español.') print ("") opcion = input("Por favor, seleccione el idioma en el que se supone que se cifró el texto en claro: ") if opcion == "1": idioma = "Inglés" elif opcion == "2": idioma = "Español" else: print ("*** ERROR: Opción no válida.") print ("") print ("[+] Idioma:", idioma) # SELECCIÓN DE ALFABETO: # Se solicita que se indique el alfabeto a emplear. if idioma == "Inglés": opcion = "1" alfabeto = "ABCDEFGHIJKLMNOPQRSTUVWXYZ" else: alfabeto = "" while alfabeto == "": print ("") print ("*** SELECCIÓN DE ALFABETO ************************") print ('1. Alfabeto de 26 caracteres ("Ñ" excluida).') print ('2. Alfabeto de 27 caracteres ("Ñ" incluida).') print ("") opcion = input("Por favor, seleccione el alfabeto a utilizar: ") if opcion == "1": alfabeto = "ABCDEFGHIJKLMNOPQRSTUVWXYZ" elif opcion == "2": alfabeto = "ABCDEFGHIJKLMNÑOPQRSTUVWXYZ" else: print ("*** ERROR: Opción no válida.") print ("") alfabeto_seleccionado = opcion print ("[+] Alfabeto:", alfabeto) print ("[+] Tamaño del alfabeto (n):", len(alfabeto)) # MENÚ: # Se presenta el menú para que se seleccione una opción. salir = False while not salir: print ("") print ("*** MENÚ *****************************************") print ("1. Ataque método Kasiski al cifrado de Vigenère.") print ("2. Salir.") print ("") opcion = input("Por favor, seleccione una opción: ") if opcion == "1": print ("") print ("--- ATAQUE MÉTODO KASISKI:") # Se introduce el criptograma. Se convierten los caracteres a mayúsculas y # se eliminan los espacios, las tildes, diéresis, etc. criptograma = "*" while not criptograma.isalpha(): criptograma = input('Criptograma a atacar: ').upper() criptograma = criptograma.replace(' ','') if alfabeto_seleccionado == "1": criptograma = criptograma.replace('Ñ','N') criptograma = re.sub(r"([^n\u0300-\u036f]|n(?!\u0303(?![\u0300-\u036f])))[\u0300-\u036f]+", r"\1", normalize("NFD", criptograma), 0, re.I) criptograma = normalize("NFC", criptograma) if criptograma.isalpha(): print ("[+] Criptograma a atacar:", criptograma) longitud_secuencias = 3 secuencias_repetidas,gcd = busqueda_secuencias_repetidas(criptograma,longitud_secuencias) if len(secuencias_repetidas) > 0: print("[+] Máximo común divisor de las distancias entre secuencias de 3 o más caracteres repetidas en el criptograma:",gcd) opcion = "" while gcd == 1 and opcion != "N": while opcion != "S" and opcion != "N": opcion = input('[+] No es posible calcular la longitud de la clave. ¿Desea probar con un tamaño de secuencias repetidas mayor (S/N)?: ').upper() if opcion == "S": longitud_secuencias+=1 print("[+] Probando con tamaño de secuencias repetidas igual o mayor que", longitud_secuencias) secuencias_repetidas,gcd = busqueda_secuencias_repetidas(criptograma,longitud_secuencias) if len(secuencias_repetidas) > 0: print("[+] Máximo común divisor de las distancias entre secuencias de caracteres repetidas en el criptograma:",gcd) else: print("[+] No se han encontrado más secuencias de caracteres repetidas en el criptograma.") opcion = "N" if gcd != 1: subcriptogramas = [] inicio_subcriptograma = 0 for subcriptograma in range(0, gcd): subcriptograma = "" for caracter in range(inicio_subcriptograma, len(criptograma), gcd): subcriptograma = subcriptograma + criptograma[caracter] subcriptogramas.append(subcriptograma) inicio_subcriptograma += 1 frecuencia_relativa = [] for subcriptograma in subcriptogramas: frecuencia_relativa.append(calculo_frecuencia_relativa(subcriptograma,alfabeto)) if idioma == "Inglés": distribucion = [0, 4, 19] else: distribucion = [0, 4, 15] frecuencias_distribucion = [] for i in range(0, len(subcriptogramas)): for j in range(0,len(alfabeto)): suma_frecuencias = 0 for k in range(0, len(distribucion)): suma_frecuencias = suma_frecuencias + frecuencia_relativa[i][0][(j+distribucion[k])%len(alfabeto)][1] frecuencias_distribucion.append(suma_frecuencias) frecuencias_distribucion = [frecuencias_distribucion[i*len(alfabeto):(i+1)*len(alfabeto)] for i in range(0, len(subcriptogramas))] caracteres_probables_clave = [] for i in range(0, len(subcriptogramas)): for j in range(0, 3): caracteres_probables_clave.append(alfabeto[frecuencias_distribucion[i].index(max(frecuencias_distribucion[i]))]) frecuencias_distribucion[i][frecuencias_distribucion[i].index(max(frecuencias_distribucion[i]))] = 0 caracteres_probables_clave = [caracteres_probables_clave[i*3:(i+1)*3] for i in range(0, len(subcriptogramas))] clave_probable = "" for i in range(0, len(subcriptogramas)): clave_probable+=caracteres_probables_clave[i][0] print("[+] El texto en claro obtenido con la clave más probable -",clave_probable,"- es:") print(descifrar(alfabeto,criptograma,clave_probable)) opcion = "" while opcion !="S" and opcion !="N": opcion = input('¿Es inteligible el texto claro obtenido (S/N)?: ').upper() if opcion == "N": while opcion !="C" and opcion !="F" and opcion !="S": opcion = input('¿Cambio manual de clave o ataque de fuerza bruta a los caracteres de la misma o fin ataque (C/F/S)?: ').upper() if opcion == "C": print("--- CAMBIO MANUAL DE LA CLAVE:") print("[+] La clave más probable es: ",clave_probable, "y los caracteres más probables de cada uno de sus caracteres son:") print(caracteres_probables_clave) # Se introduce la nueva clave a probar. Se convierten los caracteres a mayúsculas y # se eliminan los espacios, las tildes, diéresis, etc. nueva_clave_probable = "*" while not nueva_clave_probable.isalpha() or len(nueva_clave_probable) > len(subcriptogramas): nueva_clave_probable = input('Por favor, introduzca la nueva clave a probar: ').upper() nueva_clave_probable = nueva_clave_probable.replace(' ','') nueva_clave_probable = re.sub(r"([^n\u0300-\u036f]|n(?!\u0303(?![\u0300-\u036f])))[\u0300-\u036f]+", r"\1", normalize("NFD", nueva_clave_probable), 0, re.I) nueva_clave_probable = normalize("NFC", nueva_clave_probable) if nueva_clave_probable.isalpha() and len(nueva_clave_probable) <= len(subcriptogramas): print ("[+] Nueva clave a probar:", nueva_clave_probable) print("[+] El texto en claro obtenido con la nueva clave introducida -",nueva_clave_probable,"- es:") print(descifrar(alfabeto,criptograma,nueva_clave_probable)) opcion = "" while opcion !="S" and opcion !="N": opcion = input('¿Es inteligible el texto claro obtenido (S/N)?: ').upper() if opcion == "S": print("*** FIN: El ataque ha finalizado.") else: print ("*** ERROR: La nueva clave a probar sólo debe contener caracteres alfabéticos y debe tener un tamaño menor o igual que ",len(subcriptogramas)) elif opcion == "F": print("--- ATAQUE DE FUERZA BRUTA CON TODAS LAS COMBINACIONES DE CARACTERES MÁS PROBABLES DE LA CLAVE:") posibles_soluciones = [] if idioma == "Inglés": f_diccionario = open("english_dict.txt") f_trigramas = open("english_trig.txt") f_palabras = open("english_word.txt") else: f_diccionario = open("espanol_dicc.txt") f_trigramas = open("espanol_trig.txt") f_palabras = open("espanol.pala.txt") diccionario = f_diccionario.readlines() trigramas = f_trigramas.readlines() palabras = f_palabras.readlines() for i in itertools.product(*caracteres_probables_clave): texto_claro = descifrar(alfabeto,criptograma,''.join(i)) ic = calculo_ic(texto_claro,alfabeto) if ic > 0.06: puntos = 0 for trigrama in trigramas: trigrama = trigrama.strip() puntos = puntos + texto_claro.count(trigrama) for palabra in palabras: palabra = palabra.strip() puntos = puntos + texto_claro.count(palabra) * len(palabra) if puntos > 0: posibles_soluciones.append([ic, puntos, ''.join(i), texto_claro]) f_palabras.close() f_trigramas.close() f_diccionario.close() posibles_soluciones.sort(key=lambda x:x[1], reverse=True) if (len(posibles_soluciones)) > 0: print("[+] Descifrado más inteligible. 1 .- Clave: ", posibles_soluciones[0][2], "--> Texto en claro: ", posibles_soluciones[0][3]) if (len(posibles_soluciones)) > 1: mostrar_10_mas = "S" inicio_siguientes = 1 while mostrar_10_mas == "S": mostrar_10_mas = input("¿Mostrar los siguientes 10 descifrados más inteligibles ('S')?: ").upper() if mostrar_10_mas == "S": fin_siguientes = inicio_siguientes + 10 if fin_siguientes > len(posibles_soluciones): fin_siguientes = len(posibles_soluciones) for posible_solucion in range(inicio_siguientes, fin_siguientes): print(posible_solucion+1, ".- Clave: ", posibles_soluciones[posible_solucion][2], "; Texto en claro-->", posibles_soluciones[posible_solucion][3]) if fin_siguientes == len(posibles_soluciones): print("*** FIN: No hay más posibles soluciones.") mostrar_10_mas = "N" else: inicio_siguientes+=10 else: print("[+] No se han encontrado posibles descifrados inteligibles.") elif opcion == "S": print("*** FIN: El ataque ha finalizado.") elif opcion == "S": print("*** FIN: El ataque ha finalizado.") else: opcion = "" else: print("*** FIN: El máximo común divisor de las distancias que separan las secuencias de caracteres repetidas en el criptograma es 1.") else: print("*** FIN: No se han encontrado secuencias de caracteres repetidas en el criptograma.") else: print ("*** ERROR: El criptograma a atacar sólo debe contener caracteres alfabéticos.") elif opcion == "2": print ("*** FIN ******************************************") salir = True else: print ("*** ERROR: Opción no válida.") if __name__ == '__main__': main()
Lo ejecuto:
En el ejemplo de ejecución que voy a poner selecciono el español como idioma y el alfabeto de 27 caracteres ("Ñ" incluida).
Tras introducir el criptograma e iniciar el ataque, se me advierte de que no es posible calcular la longitud de la clave, ya que el máximo común divisor de las distancias que separan las secuencias repetidas de 3 o más caracteres en el criptograma es 1, y se me da la posibilidad de intentarlo con un tamaño de secuencias mayor.

Selecciono que sí deseo probar con un tamaño de secuencias repetidas mayor y se me indica que el máximo común divisor para el tamaño de secuencias repetidas (se prueba con un tamaño de 4 caracteres o más, ya que inicialmente se ha probado con 3 o más) es 5, y veo que ya se ha descifrado correctamente el criptograma. El script ha probado la clave más probable conforme a la regla "EAO" aplicada a los resultados obtenidos en el análisis de frecuencias de los caracteres en cada uno de los 5 subcriptogramas (máximo común divisor) en los que ha dividido el criptograma y me muestra el texto en claro, que veo que es correcto.
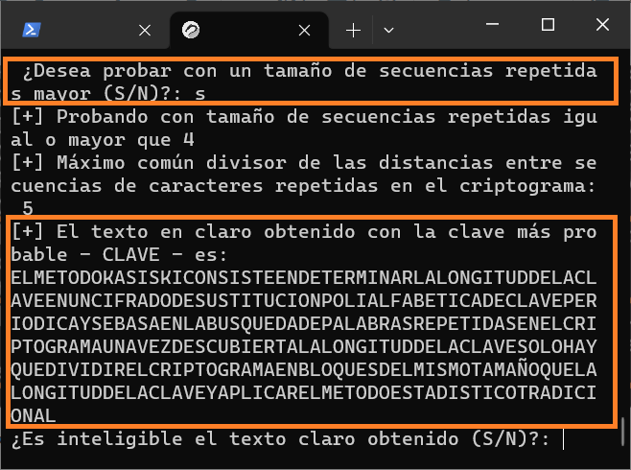
Pero, supongamos que este primer descifrado no fuera correcto. Entonces, selecciono que el texto claro obtenido no es legible y, justo después, que deseo cambiar la clave de forma manual. Como he dicho antes, esto está previsto para el caso de que tras el primer descifrado sea relativamente fácil ver a simple vista qué carácter o caracteres de la clave son incorrectos. En este ejemplo, como la clave es correcta, "CLAVE", tras ver los caracteres más probables de cada uno de los de la clave, vuelvo a poner la misma y observo que también se descifra correctamente el criptograma.

Pero, supongamos que tampoco se descifra correctamente tras cambiarse la clave manualmente. Entonces, selecciono que el texto claro obtenido no es inteligible y, justo después, que deseo probar la fuerza bruta con todas las combinaciones de caracteres de la clave, y veo que también se descifra correctamente el criptograma.

Tras el ataque de fuerza bruta, el script ha obtenido correctamente el texto en claro más inteligible de entre todos los que considera posibles, pero si no fuera correcto da la posibilidad de ver los siguientes más inteligibles en base al Índice de Coincidencia calculado para cada texto en claro descifrado y los puntos asignados en función de los trigramas y palabras incluidos en cada uno de ellos.
Comentarios
Publicar un comentario