

El enunciado del reto es el siguiente: Supón que te haces con el telegrama cifrado que se proporciona como recurso asociado al reto y que no tienes ni idea de la clave con la que fue cifrado, la desconoces por completo. Además, se trata de un criptograma relativamente corto por lo que la utilización de un método de criptoanálisis que se base únicamente en la estadística del lenguaje y/o un ataque de diccionario ('dictionary attack') puede no tener excesivo éxito. Sin embargo, sospechas que en el proceso de cifrado los homófonos no fueron seleccionados aleatoriamente, sino de forma secuencial. ¿Puedes descifrarlo?
Y como recurso asociado al reto se proporciona el siguiente:
Criptograma:
1529 0230 0423 5709 1905 2249 1412 4713 3420 5878
6900 8168 8560 0231 6693 4633 2982 5419 1688 0904
5035 9920 0349 7972 1330 9812 6905 5246 8233 7888
2209 5754 8136 9347 2485 0013 6804 4566 1949 2835
0220 6944 8130 6079 9382 5247 1909 4905 6146 1088
2281 0469 1529 6800 2091 5702 9354 3630 1982 7946
3449 0978 6943 9982 8850 2604 0581
Nota: Para este reto se ha partido del criptograma del reto anterior, en el que se han incluido unos pocos homófonos y se han corregido otros pocos, pero en este reto se pide que para criptoanalizarlo nos hagamos a la idea de que desconocemos completamente la clave empleada en el cifrado.
Solución: En el post en el que planteé este reto decía que la selección secuencial de los homófonos, en lugar de realizar ésta de forma aleatoria, no sólo ahondaba en las vulnerabilidades ya conocidas de este criptosistema (ver este post donde indiqué las principales de ellas), sino que, además, proporcionaba a los criptoanalistas una información muy útil que les podía permitir criptoanalizar con éxito los mensajes, incluso si no conocían nada de la clave empleada en el cifrado y éstos eran relativamente cortos.
Cuando comentaba que este sistema de selección ahondaba en las vulnerabilidades del cifrado de cinta móvil me refería a que, con independencia del tamaño del criptograma, al elegirse los homófonos de forma secuencial cada uno de ellos presentará una frecuencia de aparición muy aproximada a 1/4 con respecto a la letra del alfabeto del texto en claro a la que sustituye (aunque con pocos homófonos posiblemente no nos dé información muy precisa sobre la letra concreta y sólo nos indique si se trata de una letra de alta, media o baja frecuencia de aparición), mientras que en caso de selección aleatoria esto sólo sería teóricamente así en el caso de criptogramas lo suficientemente largos. Es decir, aunque el criptograma del reto tiene sólo una longitud de 134 caracteres, si multiplico por 4 la frecuencia de aparición en el criptograma de cada homófono podré hacerme una idea aproximada de la letra del alfabeto del texto en claro a la que sustituye cada uno de ellos o, al menos, de si se trata de una letra de alta, media o baja frecuencia de aparición.
En primer lugar voy a ver la frecuencia de aparición de los homófonos en el criptograma (en la siguiente figura ubico la tabla horizontalmente en dos mitades para que se vea completa en el menor espacio posible):

Si esto fuera así puedo intentar recomponer parte de las columnas de la tabla de homófonos empleada en el proceso de cifrado, de la siguiente manera:
1.- Busco todos los homófonos de la primera decena (del '00' al '09) que aparecen en el criptograma y se repiten al menos dos veces (los homófonos de la primera decena que se repiten se resaltan en la figura siguiente con el color que les corresponde en la tabla anterior conforme a su frecuencia de aparición):

- Para el homófono '00':
H('00', 1) = {81, 68,
85, 60, 31, 66, 93, 46, 33, 29, 82, 54, 19, 16, 88, 50, 35, 99, 20, 49, 79, 72, 13, 30, 98, 12, 69, 52, 46, 82, 33, 78, 88, 22, 57, 54,
81, 36, 93, 47, 24, 85}
H('00', 2) = {13, 68, 45, 66, 19, 49, 28, 35, 20, 69, 44, 81, 30, 60, 79, 93, 82, 52, 47, 19, 49, 61, 46, 10, 88, 22, 81, 69, 15, 29, 68}
H('00', 3) = {20, 91,
57, 93, 54, 36, 30, 19, 82, 79, 46, 34, 49, 78, 69, 43, 99, 82, 88, 50,
26, 81}
- Para el homófono '02':
H('02', 1) = {30, 23, 57, 19, 22, 49, 14, 12, 47, 13, 34, 20, 58, 78, 69, 81, 68, 85,
60}
H('02', 2) = {31, 66,
93, 46, 33, 29, 82, 54, 19, 16, 88, 50, 35, 99, 20, 49, 79, 72, 13,
30, 98, 12, 69, 52, 46, 82, 33, 78, 88, 22, 57, 54, 81, 36, 93, 47, 24,
85, 13, 68, 45, 66, 19, 49, 28, 35}
H('02', 3) = {20, 69,
44, 81, 30, 60, 79, 93, 82, 52, 47, 19, 49, 61, 46, 10, 88, 22, 81,
69, 15, 29, 68, 20, 91, 57}
H('02', 4) = {93, 54,
36, 30, 19, 82, 79, 46, 34, 49, 78, 69, 43, 99, 82, 88, 50, 26, 81}
- Para el homófono '04':
H('04', 1) = {23, 57, 19, 22, 49, 14, 12, 47, 13, 34, 20, 58, 78, 69, 81, 68, 85, 60,
31, 66, 93, 46, 33, 29, 82, 54, 19, 16, 88}
H('04', 2) = {50, 35,
99, 20, 49, 79, 72, 13, 30, 98, 12, 69, 52, 46, 82, 33, 78, 88, 22,
57, 54, 81, 36, 93, 47, 24, 85, 13, 68}
H('04', 3) = {45, 66,
19, 49, 28, 35, 20, 69, 44, 81, 30, 60, 79, 93, 82, 52, 47, 19, 49,
61, 46, 10, 88, 22, 81}
H('04', 4) = {69, 15,
29, 68, 20, 91, 57, 93, 54, 36, 30, 19, 82, 79, 46, 34, 49, 78, 69,
43, 99, 82, 88, 50, 26}
H('04', 5) = {81}
- Para el homófono '05':
H('05', 1) = {22, 49,
14, 12, 47, 13, 34, 20, 58, 78, 69, 81, 68, 85, 60, 31, 66, 93, 46, 33,
29, 82, 54, 19, 16, 88, 50, 35, 99, 20, 49, 79, 72, 13, 30, 98, 12,
69}
H('05', 2) = {52, 46,
82, 33, 78, 88, 22, 57, 54, 81, 36, 93, 47, 24, 85, 13, 68, 45, 66,
19, 49, 28, 35, 20, 69, 44, 81, 30, 60, 79, 93, 82, 52, 47, 19, 49}
H('05', 3) = {61, 46,
10, 88, 22, 81, 69, 15, 29, 68, 20, 91, 57, 93, 54, 36, 30, 19, 82,
79, 46, 34, 49, 78, 69, 43, 99, 82, 88, 50, 26}
H('05', 4) = {81}
- Para el homófono '09':
H('09', 1) = {19,
22, 49, 14, 12, 47, 13, 34, 20, 58, 78, 69, 81, 68, 85, 60, 31, 66, 93,
46, 33, 29, 82, 54, 19, 16, 88}
H('09', 2) = {50,
35, 99, 20, 49, 79, 72, 13, 30, 98, 12, 69, 52, 46, 82, 33, 78, 88, 22}
H('09', 3) = {57, 54,
81, 36, 93, 47, 24, 85, 13, 68, 45, 66, 19, 49, 28, 35, 20, 69, 44,
81, 30, 60, 79, 93, 82, 52, 47, 19}
H('09', 4) = {49,
61, 46, 10, 88, 22, 81, 69, 15, 29, 68, 20, 91, 57, 93, 54, 36, 30,
19, 82, 79, 46, 34, 49}
H('09', 5) = {78, 69,
43, 99, 82, 88, 50, 26, 81}
3.- Por la condiciones impuestas por el método de elección secuencial, en todos los conjuntos obtenidos para cada uno de los homófonos de la primera decena, excepto en el último que no está completo, deben estar el resto de los homófonos que conforman con él la misma columna, es decir, los homófonos que junto con él representan en el criptograma a la misma letra del alfabeto del texto en claro. Por tanto, en primer lugar, busco aquellos homófonos que se repiten una única vez en cada conjunto (si se repite más de una, por las condiciones ya mencionadas del propio método, lo desecho como integrante de la misma columna). Debe repetirse una vez en todos los conjuntos de cada uno de los homófonos de la primera decena, aunque como digo puede no repetirse en el último.
- Comienzo por los conjuntos del homófono '09' porque éste es uno de los de la primera decena con mayor frecuencia de aparición (14,93%) y porque H('09', 2) tiene el menor número de homófonos de todos ellos, últimos conjuntos de cada homófono excluidos:
H('09',
1) = {20, 69, 82}
H('09', 2) = {20, 69, 82}
H('09',
3) = {20, 69, 82}
H('09', 4) = {69, 20, 82}
H('09',
5) = {69, 82}
Como se observa el homófono '20' no puede ser uno de los integrantes de esta columna, por dos motivos: debería preceder al homófono '69' en H('09', 4) y en H('09', 5), ya que otra de las condiciones impuestas por el método de elección secuencial es que los homófonos deben seguir un orden ascendente, y, además, tal y como se ve en la siguiente figura, presenta un porcentaje de aparición inferior a los homófonos '69' y '82', lo que no es posible con la elección secuencial (todos los homófonos de una misma columna deben tener esa frecuencia igual o mayor que la de los homófonos de la misma columna a los que preceden).

Por tanto, ya he reconstruido una de las columnas de la tabla de homófonos empleada en el proceso de cifrado: C1 = {09, 69, 82}. Lo que, además, encaja muy bien: entre 3 y 5 homófonos por columna y con una frecuencia de aparición de los homófonos en el criptograma igual o parecida.
- Continúo por los conjuntos del homófono '04' porque éste es el siguiente de los de la primera decena con mayor frecuencia de aparición (14,93%). De dichos conjuntos quito, además de los homófonos correspondientes a la primera decena, aquellos ya asignados en el paso anterior:
H('04', 1) = {20, 93, 46, 88}
H('04', 2) = {20, 46, 88, 93}
H('04', 3) = {20, 93, 46, 88}
H('04', 4) = {20, 93, 46, 88}
Como se observa el homófono '93' no puede formar parte de la misma columna con '46', ni con '88', ya que como he dicho anteriormente los homófonos de una misma columna deben seguir un orden ascendente en todos los conjuntos. Por tanto, aunque la columna podría estar formada por los homófonos '04', '20' y '93', creo que, porque serían 4 en lugar de 3 los homófonos integrantes de la misma columna, es más probable que la conformen los siguientes:

Por tanto, de momento, voy a considerar que otra de las columnas de la tabla de homófonos empleada en el proceso de cifrado es C2 = {04, 20, 46, 88}. Lo que, además, encaja muy bien: entre 3 y 5 homófonos por columna (de media 4) y con una frecuencia de aparición de los homófonos en el criptograma igual o parecida.
- Sigo con los conjuntos del homófono '02' porque éste es el siguiente de los de la primera decena con mayor frecuencia de aparición (11,94%) y porque H('02', 1) tiene menor número de homófonos que los conjuntos del homófono '05', últimos conjuntos de ambos homófonos excluidos. Al igual que en el caso previo, de los conjuntos del homófono '02' quito, además de los correspondientes a la primera decena, aquellos ya asignados en los pasos anteriores:
H('02', 1) = {30, 57, 22, 47, 68}
H('02', 2) = {30, 22, 57, 47, 68}
H('02', 3) = {30, 47, 22, 68, 57}
H('02', 4) = {30}
Como se observa el homófono '22' no puede formar parte de la misma columna con '30', ni con '47', ni con '57', y el homófono '57' no puede formar parte de la misma columna con '47', ni con '68' . Por tanto, aunque la columna podría estar formada por los homófonos '02', '22' y '68', o por '02', '30' y '57', creo que, porque serían 4 en lugar de 3 los homófonos integrantes de la misma columna, es más probable que la conformen los siguientes:

- Continúo con los conjuntos del homófono '05' porque es el siguiente de los de la primera decena con mayor frecuencia de aparición (11,94%). Al igual que en los casos anteriores, de los conjuntos del homófono '05' quito, además de los correspondientes a la primera decena, aquellos ya asignados en los pasos anteriores:
H('05', 1) = {22, 78, 54, 79}
H('05', 2) = {78, 22, 54, 79}
H('05', 3) = {22, 54, 79, 78}
Como se observa el homófono '78' no puede formar parte de la misma columna con '22', ni con '54', ni con '79, y el homófono '54' no puede formar parte de la misma columna con '78' . Por tanto, creo que lo más probable es que los homófonos integrantes de la misma columna sean:

Por tanto, ya he reconstruido otra de las columnas de la tabla de homófonos empleada en el proceso de cifrado: C4 = {05, 22, 54, 79}. Lo que, además, encaja muy bien: entre 3 y 5 (de media 4) homófonos por columna y con una frecuencia de aparición de los homófonos en el criptograma igual o parecida.
- Continúo con los conjuntos del homófono '00', último de los de la primera decena que se repite en el criptograma (frecuencia de aparición: 2,24%). Al igual que en los casos anteriores, de los conjuntos del homófono '00' quito, además de los correspondientes a la primera decena, aquellos ya asignados en los pasos anteriores:
H('00', 1) = {60, 66, 29, 35, 13, 52}
H('00', 2) = {13, 66, 35, 60, 52, 29}
Como se observa el homófono '29' no puede formar parte de la misma columna con ninguno del resto de homófonos candidatos a formar parte de la columna con '00', por lo que lo desecho; los homófonos '60' y '66' pertenecen a la misma decena, por lo que ambos no pueden formar parte de la misma columna, e individualmente ninguno de ambos puede formar parte de la misma columna con ninguno del resto de homófonos candidatos, por lo que los desecho; el homófono 13 sólo podría formar parte de la misma columna con '52'; y el homófono '35 ' sólo podría formar parte de la misma columna con '52'. Es decir, existen dos posibilidades (en cualquier caso, parece que '00' y '35' forman parte de la misma columna):

Por tanto, de momento, voy a considerar que otra de las columnas de la tabla de homófonos empleada en el proceso de cifrado es C5 = {00, 13, 35}. Lo que, al igual que en la otra opción, encaja muy bien: entre 3 y 5 homófonos por columna y con una frecuencia de aparición de los homófonos en el criptograma igual o parecida.
3.- Repito los dos puntos anteriores para la siguiente decena, es decir, busco todos los homófonos de la segunda decena (del '10' al '19) que aparecen en el criptograma y se repiten al menos dos veces (el color de los homófonos de la segunda decena que se repiten se resaltan en la figura siguiente con el color que les corresponde en la tabla de análisis de frecuencias conforme a su frecuencia de aparición):

4.- con los mismos criterios que en el caso de la primera decena, formo conjuntos con los homófonos que están entre cada uno de los homófonos de la segunda decena que se repiten en el criptograma:
- Para el homófono '13' (lo considero, pese a haber sido asignado anteriormente, para ver si me despeja la duda que me surge respecto a la columna C5, para la que existen dos posibilidades):
H('13', 1) = {34, 20,
58, 78, 69, 00, 81, 68, 85, 60, 02, 31, 66, 93, 46, 33, 29, 82, 54, 88,
09, 04, 50, 35, 99, 20, 03, 49, 79, 72}
H('13', 2) = {30, 98, 69, 05, 52, 46, 82, 33, 78, 88, 22, 09, 57, 54, 81, 36, 93, 47, 24, 85, 00}
H('13', 3) = {68, 04,
45, 66, 49, 28, 35, 02, 20, 69, 44, 81, 30, 60, 79, 93, 82, 52, 47, 09,
49, 05, 61, 46, 88, 22, 81, 04, 69, 29, 68, 00, 20, 91, 57, 02, 93, 54,
36, 30, 82, 79, 46, 34, 49, 09, 78, 69, 43, 99, 82, 88, 50, 26, 04, 05, 81}
- Para el homófono '19':
H('19', 1) = {05, 22,
49, 47, 34, 20, 58, 78, 69, 00, 81, 68, 85, 60, 02, 31, 66, 93, 46,
33, 29, 82, 54}
H('19', 2) = {88,
09, 04, 50, 35, 99, 20, 03, 49, 79, 72, 30, 98, 69, 05, 52, 46, 82, 33,
78, 88, 22, 09, 57, 54, 81, 36, 93, 47, 24, 85, 00, 68, 04, 45, 66}
H('19', 3) = {49, 28,
35, 02, 20, 69, 44, 81, 30, 60, 79, 93, 82, 52, 47}
H('19', 4) = {09, 49,
05, 61, 46, 88, 22, 81, 04, 69, 29, 68, 00, 20, 91, 57, 02, 93, 54, 36,
30}
H('19', 5) = {82, 79,
46, 34, 49, 09, 78, 69, 43, 99, 82, 88, 50, 26, 04, 05, 81}
- Comienzo por los conjuntos del homófono '19' porque es el que mayor frecuencia de aparición (14,93%) presenta de entre los de la segunda decena:
H('19', 1) = {49, 81, 93}
H('19', 2) = {49, 81, 93}
H('19', 3) = {49, 81, 93}
H('19', 4) = {49, 81, 93}
H('19', 5) = {49, 81}
Con lo que parece claro que la columna estaría formada por los siguientes homófonos:

Por tanto, ya he reconstruido otra de las columnas de la tabla de homófonos empleada en el proceso de cifrado: C6 = {19, 49, 81, 93}. Lo que, además, encaja muy bien: entre 3 y 5 homófonos por columna (de media 4) y con una frecuencia de aparición de los homófonos en el criptograma igual o parecida.
- Sigo por los conjuntos del homófono '13' porque es el siguiente que mayor frecuencia de aparición (8,96%) presenta de entre los de la segunda decena:
H('13', 1) = {78, 85, 33}
H('13', 2) = {33,78, 85}
H('13', 3) = {78}
Con lo que parece claro que la columna estaría formada por los homófonos cuyo fondo está resaltado en color verde, ya que '33' no puede estar en la misma columna ni con '78' ni con '85':
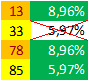
Por tanto, ya he reconstruido otra de las columnas de la tabla de homófonos empleada en el proceso de cifrado: C7= {13, 78, 85}. Lo que, además, encaja muy bien: entre 3 y 5 homófonos por columna y con una frecuencia de aparición de los homófonos en el criptograma igual o parecida. Además, este resultado podría haberme resuelto la duda sobre la columna C5, para la que existen dos posibilidades, por lo que la corrijo de la siguiente manera: C5 = {00, 35, 52}
5.- Repito los dos puntos anteriores para la siguiente decena, es decir, busco todos los homófonos de la tercera decena (del '20' al '29) que aparecen en el criptograma y se repiten al menos dos veces (el color de los homófonos de la tercera decena que se repiten se resaltan en la figura siguiente con el color que les corresponde en la tabla de análisis de frecuencias conforme a su frecuencia de aparición):

6.- Con los mismos criterios que en el caso de las dos primeras decenas, formo conjuntos con los homófonos que están entre cada uno de los homófonos de la tercera decena que se repiten en el criptograma:
- Desecho el homófono '20' por ya estar asignado a la columna C2 = {04, 20, 46, 88}.
- Desecho el homófono '22' por ya estar asignado a la columna C4 = {05, 22, 54, 79}:
- Para el homófono '29:
H('29', 1) = {02, 30,
04, 57, 09, 19, 05, 49, 14, 12, 47, 13, 34, 58, 78, 69, 00, 81, 68,
85, 60, 02, 31, 66, 93, 46, 33}
H('29', 2) = {82, 54,
19, 16, 88, 09, 04, 50, 35, 99, 03, 49, 79, 72, 13, 30, 98, 12, 69, 05, 52,
46, 82, 33, 78, 88, 09, 57, 54, 81, 36, 93, 47, 85, 00, 13, 68, 04, 45,
66, 19, 49, 35, 02, 69, 44, 81, 30, 60, 79, 93, 82, 52, 47, 19, 09, 49,
05, 61, 46, 10, 88, 81, 04, 69, 15}
H('29', 3) = {68, 00,
20, 91, 57, 02, 93, 54, 36, 30, 19, 82, 79, 46, 34, 49, 09, 78, 69, 43, 99, 82,
88, 50, 26, 04, 05, 81}
- Comienzo por los conjuntos del homófono '29' porque he desechado los otros dos de esta misma decena por haber sido asignados con anterioridad:
H('29', 1) = {57, 12, 60, 66, 33}
H('29', 2) = {12, 33, 57, 66, 60}
H('29', 3) = {57}
Con lo que parece claro que '33' no puede estar en la misma columna, junto con '29', ni con '57', ni con '60', ni con '66'; '12' no puede estar en la misma columna con '57'; y '60' y '66' no pueden formar parte de la misma columna, ya que pertenecen a la misma decena. Por tanto, de momento las posibilidades serían: {29, 12, 33}, {29, 12, 60}, {29, 12, 66}, {29, 57, 60}, {29, 57, 66}, es decir, existen cinco posibilidades:

Por tanto, de momento, voy a considerar que otra de las columnas de la tabla de homófonos empleada en el proceso de cifrado es C8 = {29, 57, 60}. Lo que, al igual que en las otras opciones, encaja muy bien: entre 3 y 5 homófonos por columna y con una frecuencia de aparición de los homófonos en el criptograma igual o parecida.
Y con esto ya estarían asignados todos los homófonos que aparecen en el criptograma y se repiten al menos dos veces.
Recapitulando, hasta el momento he reconstruido las siguientes columnas de la tabla de homófonos empleada en el cifrado:
C1 = {09, 69, 82}
C2 = {04, 20, 46, 88}
C3 = {02, 30, 47, 68}
C4 = {05, 22, 54, 79}
C5 = {00, 35, 52}
C6 = {19, 49, 81, 93}
C7 = {13, 78, 85}
C8 = {29, 57, 60}
En la lista anterior hay 28 homófonos y, por consiguiente, faltan 72. De los que faltan, 47 no aparecen en el criptograma, por lo que no van a tener ninguna influencia en el descifrado y puedo perfectamente desecharlos. Y el resto, 25, representarían en el criptograma a letras del alfabeto de baja frecuencia de aparición en el texto en claro (igual o menor que el 5,97%), por lo que numéricamente su influencia en el descifrado será bastante menor que la de los 28 homófonos que figuran en la lista anterior (sólo son 41 homófonos de 134, es decir, sólo suponen el 30,60% de los homófonos del criptograma, frente a (93 homófonos de 134, es decir, el 69,40%).
¿Serán suficientes esos 28 homófonos? Lo compruebo, y para ello sustituyo en el criptograma los homófonos asignados a cada columna por una letra cualquiera del alfabeto (por ejemplo una letra correlativa para cada grupo, e incluyo un guion por cada homófono que no he podido asignar a ninguna columna) y obtengo lo siguiente (utilizo la misma herramienta que en el reto anterior):

PORRAZONESSEGURIDADINTERIORQUEACONSEJANACTUALESCIRCUNSTANCIASNOSEPERMITIRAQUEEXTRANJEROSENTRENESPAÑASEANPORTADORESPRENSADENINGUNACLASE
Es decir:
POR RAZONES SEGURIDAD INTERIOR QUE ACONSEJAN ACTUALES CIRCUNSTANCIAS NO SE PERMITIRA QUE EXTRANJEROS ENTREN ESPAÑA SEAN PORTADORES PRENSA DE NINGUNA CLASE
******** PRÓXIMO RETO
Reto 48: "Fue el tercero".
Comentarios
Publicar un comentario