

Por tanto, en este post intento enmendar mi torpeza a la hora de explicarme convenientemente sobre el último paso del criptoanálisis de este tipo de mensajes cifrados, es decir, sobre el ataque simple de tipo estadístico monoalfabético en cada uno de los subcriptogramas obtenidos tras averiguar la longitud de la clave.
En primer lugar recodar que cada uno de los subcriptogramas obtenidos habrá sido cifrado con la misma letra de la clave utilizada o, lo que es lo mismo, con la misma fila de la tabla que el cifrado de Vigenère emplea para cifrar los mensajes, es decir, con el mismo alfabeto (el correspondiente a cada carácter de la clave o fila de la tabla: un máximo de 27 alfabetos diferentes si consideramos las letras del español, incluida la "Ñ").
Una duda que me preguntan es por qué consideramos las letras "A", "E" y "O". La respuesta es porque dichas letras son las más frecuentes en español, ya que el texto en claro del mensaje del primer post está escrito en español (si estuviera escrito en inglés, como es el caso del segundo post, deberíamos considerar las letras "E", "T", "A", ya que son las más frecuentes en dicho idioma).
Como digo cada subcriptograma ha sido cifrado utilizando la misma letra de la clave (fila de la tabla) y partiendo de la tabla con la frecuencia relativa de los caracteres (el número de veces que aparece cada uno de ellos) en cada subcriptograma, que era la siguiente en el primer post:

1º) En primer lugar consideremos la posición que ocupa cada una de las letras en el alfabeto español:

2º) Ahora en cada subcriptograma vamos a buscar las tres letras más frecuentes (cuya suma de sus frecuencias sea la mayor) que cumplan con esa distribución, ya que éstas serán las candidatas a ser la "A", "E" y "O" (las tres más frecuentes en español) en el texto en claro, lo que como veremos más adelante nos permitirá obtener el carácter de la clave (la fila de la tabla) con la que se cifró el subcriptograma.
Para ello nos creamos otra tabla en la que para cada subcriptograma vamos sumando para cada carácter la frecuencia relativa en la tabla anterior de ese carácter más la de aquel que se encuentra cuatro posiciones a su derecha más la de aquel que se encuentra 11 posiciones a la derecha de este último (pongo como ejemplo el primer subcriptograma):
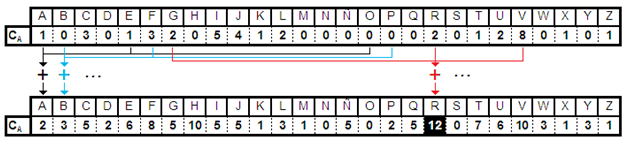
3º) ¿Por qué en el ejemplo la letra de la clave (la fila de la tabla) con la que se ha cifrado el primer subcriptograma es la "R"?.
Porque la suma mayor de las frecuencias relativas de las tres letras que cumplen con la distribución indicada se corresponde con la de las letras "R", "V" y "G", que son las candidatas a ser la "A", "E" y "O" en el texto en claro, y tal y como se observa en la siguiente figura para que esto sea así se habría utilizado la fila "R" (carácter de la clave) para cifrarlo:

Si repetimos esto para el resto de subcriptogramas nos haremos una idea bastante aproximada de cuál puede ser la clave, y en caso de duda podríamos comprobar si alguna de las posibles claves tiene algún significado (lo más probable) y, en cualquier caso, podríamos probar las posibles claves obtenidas hasta descifrar el mensaje.
En nuestro caso, si no me he equivocado, obtendríamos lo siguiente para los cuatro subcriptogramas:

Quizás también te interese:



Gracias, no entendía de donde te salían esas tres, la cosa es que, para qué poner en grupo las tres letras, déjame explicarme con un ejemplo: si en el idioma español las letras más frecuentes son AEO y en el primer subcriptograma (Ca) corresponden a RVG, la letra clave entre ellas siempre va a ser la mayor, osea la R, según el tablero Vigenére, es decir, no sería necesario saber que la letra correspondiente a E es V y la letra correspondiente a O es G, sabiendo que la letra correspondiente a A es R, en tal caso solo tendría que buscar en cada subcritograma la letra que corresponda a A, y tendría la clave; ahora mi pregunta es, si en todos los mensajes secretos elaborados con el método Vigenére para descifrarlos sin clave con el método Kasiski esto se repite.
ResponderEliminarGracias, no entendía de donde te salían esas tres, la cosa es que, para qué poner en grupo las tres letras, déjame explicarme con un ejemplo: si en el idioma español las letras más frecuentes son AEO y en el primer subcriptograma (Ca) corresponden a RVG, la letra clave entre ellas siempre va a ser la mayor, osea la R, según el tablero Vigenére, es decir, no sería necesario saber que la letra correspondiente a E es V y la letra correspondiente a O es G, sabiendo que la letra correspondiente a A es R, en tal caso solo tendría que buscar en cada subcritograma la letra que corresponda a A, y tendría la clave; ahora mi pregunta es, si en todos los mensajes secretos elaborados con el método Vigenére para descifrarlos sin clave con el método Kasiski esto se repite.
ResponderEliminarBuenas Nadia:
ResponderEliminarEfectivamente, por la tabla que utiliza este método, la primera letra de la suma mayor de frecuencias relativas de los tres caracteres que cumplen con esa distribución, (0, +4, +11) mod 27, es la letra de clave , es decir, la que en la fila de la tabla que se ha utilizado para cifrar el criptograma correspondería a la A (en nuestro ejemplo la R).
No obstante, si sólo buscamos la letra más frecuente en cada subcriptograma pensando que es la A nos equivocaremos en la mayoría de las ocasiones (hay que pensar que muchos autores dicen que la letra más frecuente en castellano es la E y, en cualquier caso, la diferencia de aparición entre estas dos letras en un texto en castellano no es muy significativa y podría llevarnos a error, máxime con subcriptogramas no muy largos), por lo que se hace necesario buscar la A,E y O cuya suma de frecuencias relativas de aparición en el subcriptograma es muy probable que sea la mayor, pero como bien dices, una vez hecho esto, la primera letra de esa mayor suma de frecuencias relativas se correspondería con la A, la segunda con la E y la tercera con la O en la fila de la tabla que se utilizó para cifrar el subcriptograma.
Incluso en ocasiones, para depurar más la búsqueda podría incluirse la S, que es la cuarta letra más frecuente en castellano.
Y respecto a tu pregunta: sí el método Kasiski sirve para descifrar cualquier mensaje cifrado con el método de Vigenère, siempre y cuando el mensaje sea lo suficientemente largo para que este método sea eficaz, aunque la cosa podría complicarse si se utiliza una clave larga.
Un saludo y muchas gracias por comentar.